开源地址:
github: https://github.com/sagframe/sagacity-sqltoy
gitee: https://gitee.com/sagacity/sagacity-sqltoy
idea 插件 (可直接在 idea 中检索安装): https://github.com/imyuyu/sqltoy-idea-plugin
sqltoy 脚手架项目:https://gitee.com/momoljw/sss-rbac-admin
sqltoy lambda 项目: https://gitee.com/gzghde/sqltoy-plus
更新内容
1、优化 mogdb 数据库支持 (由 sqltoy 用户自行扩展,信创场景)
2、在 lightdao 中增加 generateBizId 灵活通过 redis 产生业务主键
JPA 部分
类似 JPA 的对象化 CRUD、对象级联加载和新增、更新
支持通过 POJO 生成 DDL 以及直接向数据库创建表
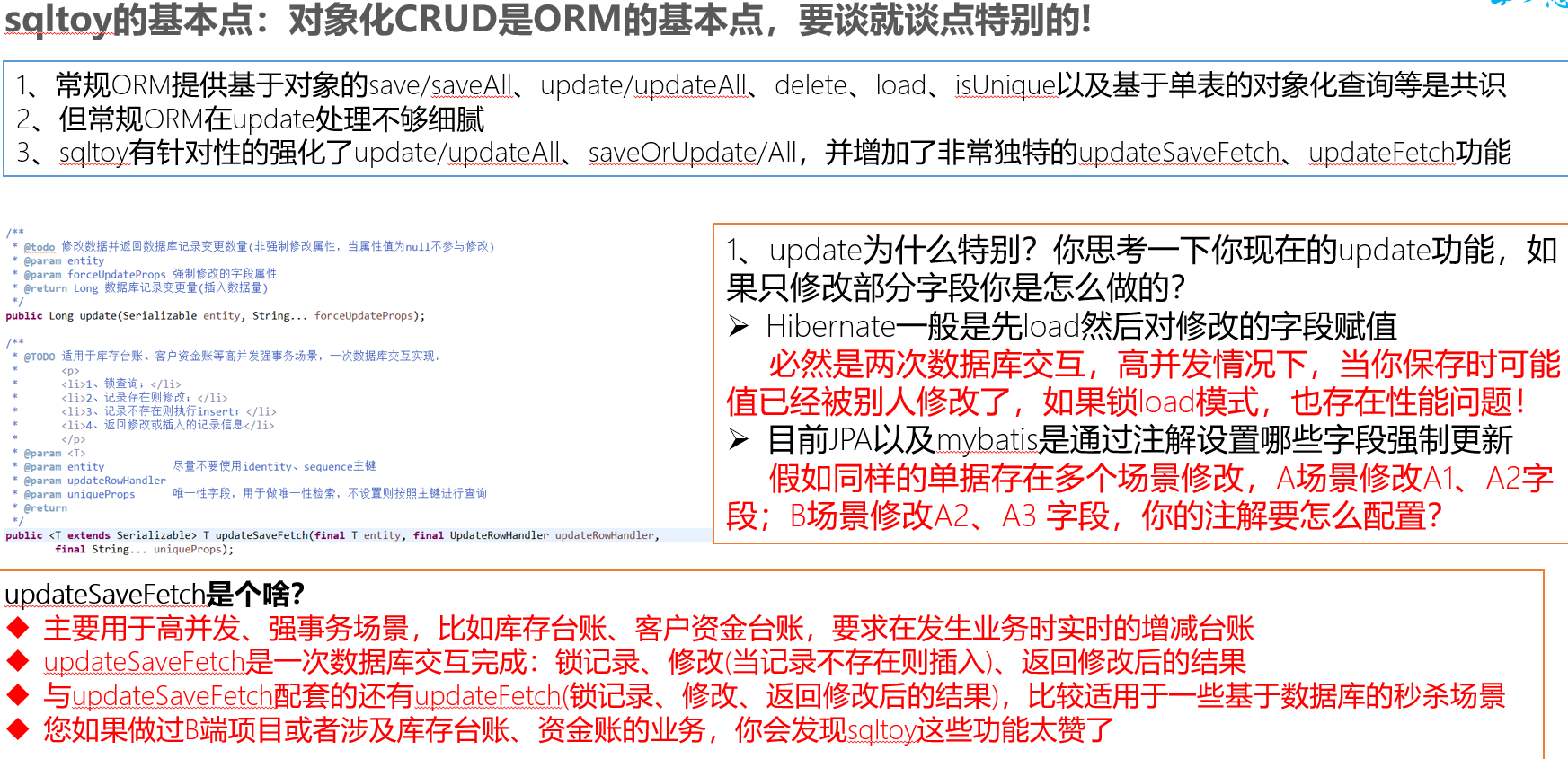
强化 update 操作,提供弹性字段修改能力,不同于 hibernate 先 load 后修改,而是一次数据库交互完成修改,确保了高并发场景下数据的准确性
改进了级联修改,提供了先删除或者先置无效,再覆盖的操作选项
增加了 updateFetch、updateSaveFetch 功能,强化针对强事务高并发场景的处理,类似库存台账、资金台账,实现一次数据库交互,完成锁查询、不存在则插入、存在则修改,并返回修改后的结果
增加了树结构封装,便于统一不同数据库树型结构数据的递归查询
支持分库分表、支持多种主键策略 (额外支持基于 redis 的产生特定规则的业务主键)、加密存储、数据版本校验
提供了公共属性赋值 (创建人、修改人、创建时间、修改时间、租户)、扩展类型处理等
提供了多租户统一过滤和赋值、提供了数据权限参数带入和越权校验
查询部分
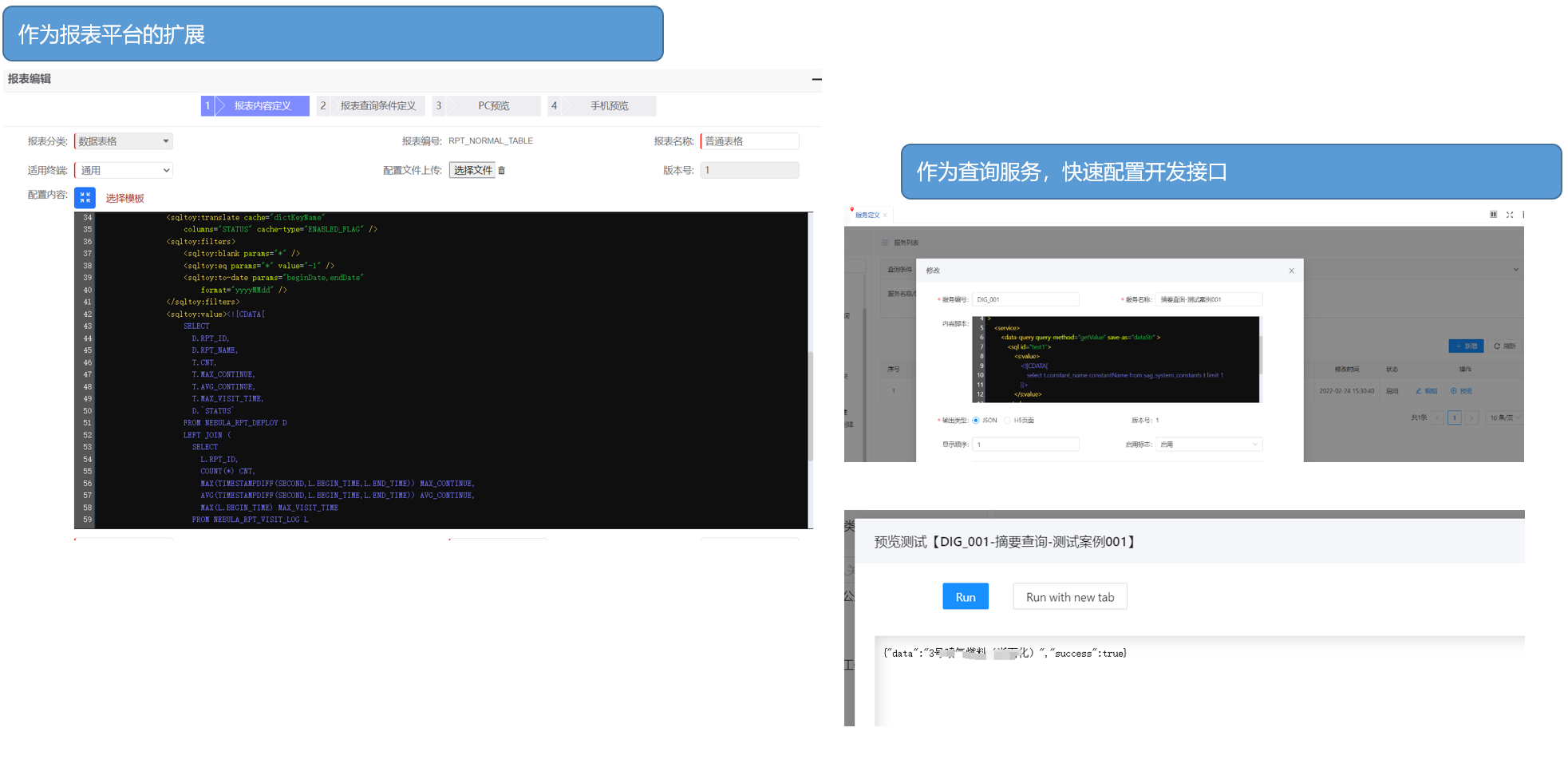
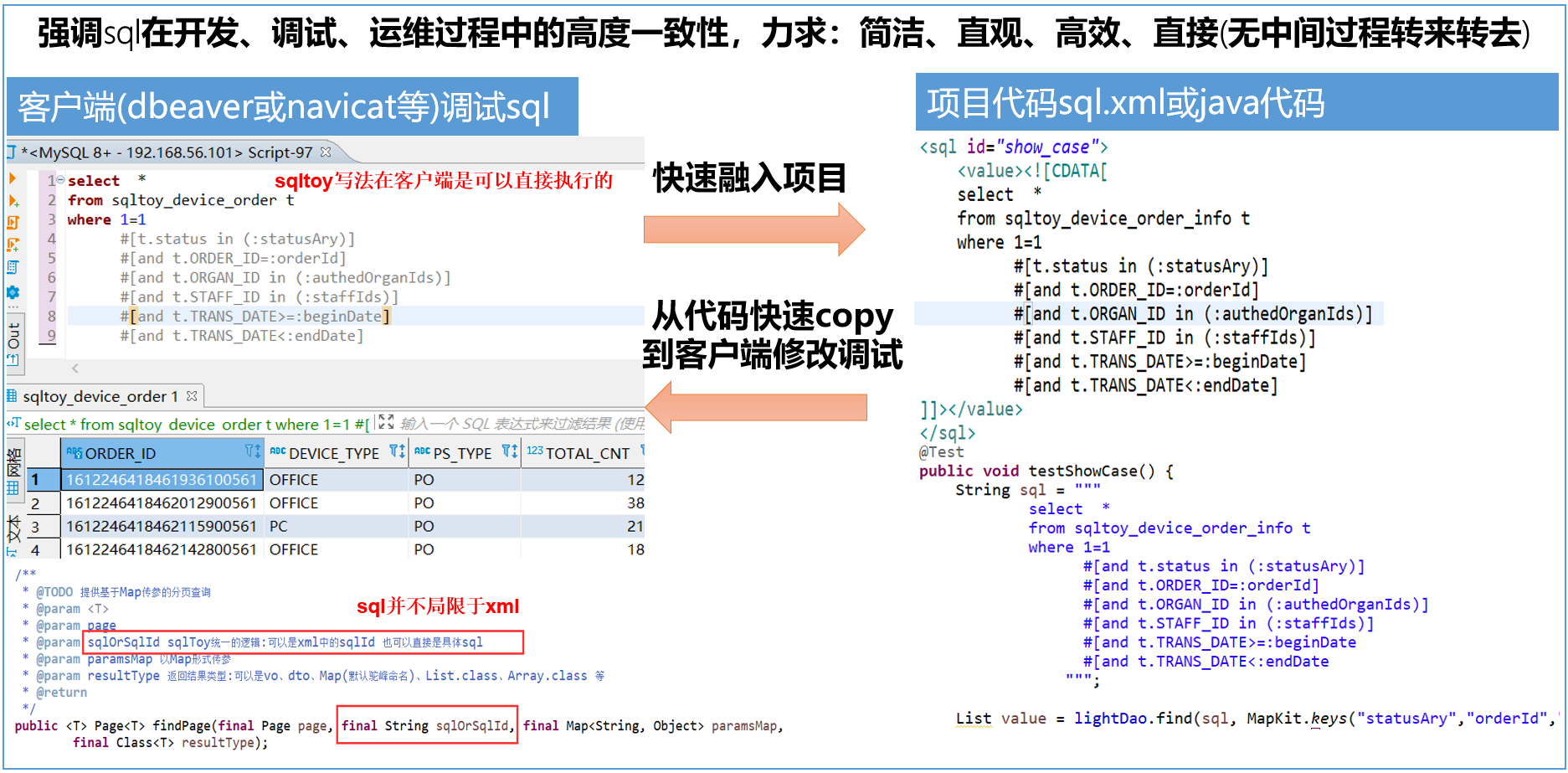
极为直观的 sql 编写方式,便于从客户端 <--> 代码 双向快速迁移,便于后期变更维护
支持缓存翻译、反向缓存匹配 key 代替 like 模糊查询
提供了跨数据库支持能力:不同数据库的函数自动转换适配,多方言 sql 根据实际环境自动匹配、多数据库同步测试,大幅提升了产品化能力
提供了取 top 记录、随机记录等特殊场景的查询功能
提供了最强大的分页查询机制:1) 自动优化 count 语句;2) 提供基于缓存的分页优化,避免每次都执行 count 查询;3) 提供了独具特色的快速分页;4) 提供了并行分页
提供了分库分表能力
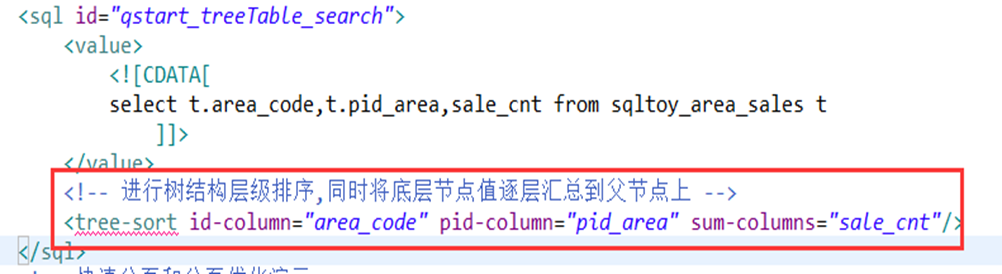
提供了在管理类项目中极为价值的:分组汇总计算、行列转换 (行转列、列转行)、同比环比、树形排序、树形汇总 相关算法自然集成
提供了基于查询的层次化数据结构封装
提供了大量辅助功能:数据脱敏、格式化、条件参数预处理等
支持多种数据库
常规的 mysql、oracle、db2、postgresql、 sqlserver、dm、kingbase、sqlite、h2、 oceanBase、polardb、guassdb、tidb
支持分布式 olap 数据库: clickhouse、StarRocks、greenplum、impala (kudu)
支持 elasticsearch、mongodb
所有基于 sql 和 jdbc 各类数据库查询
sqltoy 特点介绍:
sqltoy 的核心构建思想
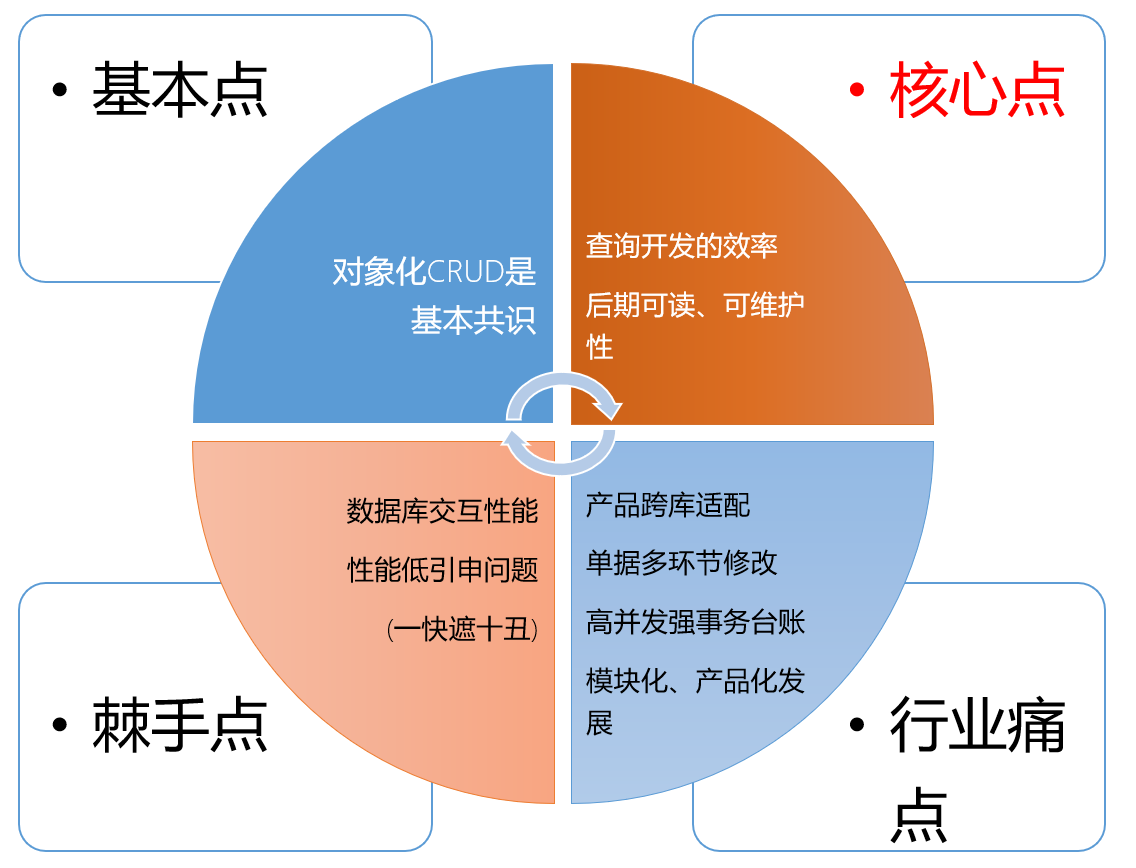
sqltoy 的对比 mybatis (plus) 的核心点:查询语句编写、可阅读性、可维护性
对象化 crud 是基础,但 sqltoy 有针对性的改进:update、updateSaveFetch、updateFetch 等
sqltoy 的缓存翻译,大幅减少表关联简化 sql,让你的查询性能成几何级提升

极致的分页,同样帮助你实现查询的性能大幅提升
快速分页:@fast () 实现先取单页数据然后再关联查询,极大提升速度
分页优化器:page-optimize 让分页查询由两次变成 1.3~1.5 次 (用缓存实现相同查询条件的总记录数量在一定周期内无需重复查询
sqltoy 的分页取总记录的过程不是简单的 select count (1) from (原始 sql);而是智能判断是否变成:select count (1) from 'from 后语句 ', 并自动剔除最外层的 order by
sqltoy 支持并行查询:parallel="true",同时查询总记录数和单页数据,大幅提升性能

便利的跨数据库统计计算:数据旋转

便利的跨数据库统计计算:无限极分组统计 (含汇总求平均)

便利的跨数据库统计计算:同比环比

5、树形表排序汇总
6、扩展集成